Before jumping onto the differences between preemptive and non-preemptive scheduling in operating system directly lets’ first have an overview about what scheduling means in operating system.What are the important terms used to define scheduling of tasks and processes in operating systems. First, We will define preemptive and non-preemptive scheduling and at the end, we will provide difference or comparison chart between them.
Scheduling in Operating Systems
In operating system the term scheduling is referred as scheduling the CPU to different (simultaneously running) processes according to their arrival time or time to completion. There are certain terms (times) in operating systems lets define them first.
- Arrival time:
The time at which the process arrives at the CPU demanding for its execution.
- Completion time:
The time at which the process leaves the CPU after its completion.
- Turnaround time:
The total time a process will need with the CPU to complete its execution, where
Turnaround time = Completion time – Arrival time
When a process runs, and it requires some I/O operations then it have to wait for that operation to terminate before returning to the CPU. The process does not perform execution at that time when it is waiting for the I/O operation to be done. In a singly programming computer systems, such condition will end up in a situation where the CPU is free and is waiting for the I/O operation to terminate. But this gives CPU a lot of rest and decreases the efficiency of the CPU to a remarkable level.
Hence, we uses multiprogramming in almost all the modern computers now, in which, while one process is waiting for the I/O operating to be done, some other processes may use the CPU for its execution at that time and the CPU may not have to wait and is used efficiently. And in order to run all the currently required processes, we schedule the processes to terminate their execution and give other processes chance to use the CPU, to fulfill the condition of multi programming i.e. all the processes have enough time to complete their execution in reasonable time.
This is what we call scheduling in operating systems. Scheduling is divided into different types depending on which process the CPU will run first and based on what conditions. These types are explained briefly below.
Types of scheduling
- First come first serve (FCFS).
- Shortest Job first (SJF).
- Shortest time to completion first (STCF).
- Round robin scheduling.
- Multilevel feedback queue.
First come first serve:
In this method the process which comes first will be executed first. It will have a large turnaround time if the longer jobs arrive first.
Shortest Job first:
The processes having the shortest turnaround time will be executed first. If short processes keep coming it will cause starvation for the longer jobs.
Shortest time to completion first:
The process whose time to completion is the minimum of all will be executed first. It has less turnaround time, but the response time is very high.
Round robin scheduling:
All the processes are executed in small portions in a round robin method i.e. a small portion of process A will be executed and then of process B and again of process A and it will continue until one or all the processes have achieved the completion of their execution. It has smaller response time but the turnaround time exceeds exceptionally. A better explanation of round robin is shown in the figure below,

Figure 1: Round robin scheduling
Multilevel feedback queue:
It is the scheduling algorithm in which processes are assigned priority numbers. Whenever a process arrives it is given the highest priority and after completing a certain (fixed by operating system) time in that queue it will move down to the lower queue. The CPU will execute the process which is in the highest queue first and then after that defined certain time it will move downwards.
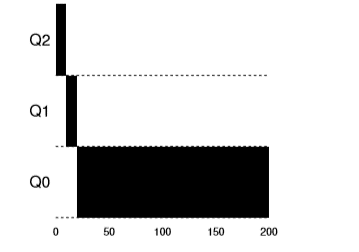
Figure 2 : Multilevel feedback queue
In multilevel feedback queue there is a large chance of starvation for the processes at the lowest priority queues. As the gamers may achieve the ability to remain in the highest priority queue as shown in the figure below,

Figure 3: MLFQ starvation
This issue can be resolved by using a priority boost to the lowest level queue after the burst time of CPU is completed as shown in the figure below,

Figure 4: MLFQ with priority boost
Lets’ now have a look on preemptive and non-preemptive scheduling.
Introduction to Preemptive scheduling
In preemptive scheduling, we can take back the CPU from the processes whenever we want to take it back. CPU is allocated to a process for only a specified or limited time and CPU will be taken back from the same time after some time, either the process has completed its execution or not.
For instance, let’s suppose, during the execution of a processes an interrupt occurs and the process to be executed in the interrupt handler have a higher priority level than the currently running process. In such case we have to take back the CPU from the process which is currently running and pause its execution for some time and give the CPU to the interrupt handler.
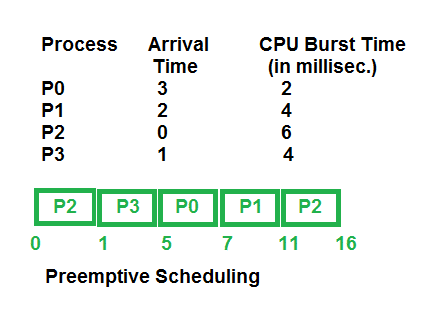
Such scheduling in which we can take back the CPU is a preemptive scheduling. Almost all of the scheduling methodology we studied in this tutorial are preemptive in nature except a few examples of preemptive scheduling are, First come first serve, Shortest job first, Shortest time to completion first, and round robin scheduling methods. The preemptive scheduling method is shown in the figure below
Introduction to Non-preemptive scheduling
In a non-preemptive scheduling algorithm, we cannot take back the CPU from a process on our will unless or until it stops its’ execution itself. Once we assign CPU to a process, it will not leave the CPU until it completes its execution, or it gets terminated or a waiting condition is reached. In this type of scheduling the process terminates or switched from running state to waiting state. This type of scheduling is a rigid type of scheduling as it has to terminate once the resources assigned to it does not end or it switches to waiting state.
The main advantage of it is that if a process is using CPU, it will never interrupt it to get CPU, it will always wait for the other process to terminate or go to waiting state to get up the resource. This way CPU does not get overloaded. The non-preemptive scheduling method we have discussed in this tutorial is Multi-level feedback queue scheduling. The non-preemptive scheduling method is shown explained briefly in the figure below,

Figure 6: Non-preemptive scheduling.
Comparison chart for preemptive and non-preemptive scheduling algorithms
Below is provided the comparison chart of preemptive and non-preemptive scheduling algorithm.
| Preemptive | Non-preemptive | |
|---|---|---|
| Definition | Processes can use CPU for a limited time. | Once a process takes CPU it will only leave it after the completion of task. |
| Overheads | It has overheads | It does not have overheads |
| Flexibility | This type of scheduling is flexible. | This type of scheduling is non-flexible. |
| Interrupts | Processing of preemptively scheduled process can be interrupted. | Processing of non-preemptive scheduling cannot be interrupted. |
| Cost | Preemptive processes are directly related to the cost of the system. | Non-preemptive processes are not related to the cost of system in any ways. |