As we have discussed in many of the previous articles that whenever we run a process, the operating system automatically allocates some space for it in memory (secondary storage). This memory allocation of a process is of major concern in operating systems. Whenever we run a process or a code the allocated space of memory can be divided into some major segments with each having its specific purpose and can store a specific type of data.
Program Memory Segments
Lets’ first discuss all the segments that are allocated memory for a program consists of.
These consists of:
- Text segment
- Initialized data segment
- Uninitialized data segment
- Stack
- Heap
The topics under concern in this article are stack and heap only however we will also have a brief look on remaining of them instead of directly jumping towards stack and heap. After that we will have a comprehensive comparison between stack and heap. The allocation of each unit of memory, written above, in the memory unit is shown in the figure below,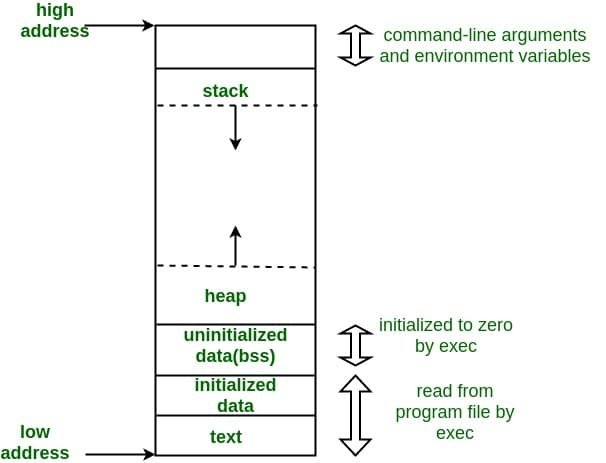
Figure 1: Memory allocation
Text segment
In memory allocation this segment plays an important role as it saves the whole code in it. Text segment is also known as code segment or simple text because it contains the complete executable code and the compiler will go through this section line by line for execution. Usually it is placed below the heap or stack in memory so that any overflow in any of them do not results in the overwriting of code section (which is not acceptable in any case).
Initialized data segment
As the name suggests, initialized data segment contains data segments or data elements which were initialized by the user. It is basically a virtual address space of the program and it not only contains variables which are initialized by the programmer but also the global and static variables as these were also in the initialized state. Note that this data segment is not read-only because the value of initialized data can be altered at run time.
Uninitialized data segment
Same again as the name suggests, this portion of memory contains uninitialized data set, i.e. the variables that were not initialized by the programmer explicitly. This segment in memory is also sometimes referred as bss “block started by symbol” segment. During the execution of the code all the variables present in this section are initialized to 0 automatically. Any uninitialized data either global, static or normal variable are placed in this section.
Now comes the major topic of discussion i.e. stack and heap, we will first have a brief discussion of the purpose and usage of each of them after that we will compare their cause.
Stack Basics
Out of all the memory blocks, this memory block is the one having quite critical functionality. Lets’ discuss its functionality first. Whenever we want to call a function, the location counter jumps to the function and leave the main code to execute the code inside the function. After the execution of the function (function call completion) the location counter return to the main code where it left the main code at the time of function call initialization. The question here is, how does the location counter know where to return after the completion of the code, and where to store the variables we initialize inside the function?
Stack Frames
Does every function create a separate memory segment for storing its data?
The answer is an obvious NO. We don’t have that large of a memory to accommodate separate section for each of a function in a thousand-line code. This data of a function is stored in the Stack. At the time of function call, the location counter pushes the return address of the main code (the line next to the function call) onto the stack, after that LC (location counter) moves to the function and push all the local variables of the function (initialized and uninitialized) onto the stack. These variables were stored into the stack as long as the LC is inside the function, at the time it exits from the function, the compiler pops all the local variables from the stack and move the LC to the return address pushed onto the stack.
The figure below, shows a simple stack and its push and pop and LIFO mechanism.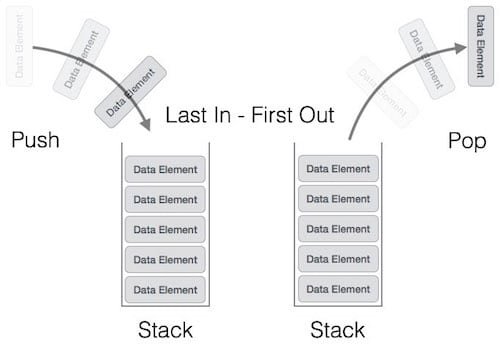
Figure 2: Stack in memory allocation
Stack Overflow
If we write a recursive function without a base condition for instance consider the example given below,
int fact(int n)
{
return n*fact(n-1);
}This piece of code will run infinite time, and each time the function is called, the compiler will push return address and local variables to the stack resulting in the overflow of stack which till result in the core dumping of program.
Heap Basics
The last memory segment in memory allocation of code is a heap. We have almost covered every section a C code may have then what is the purpose of the heap here? Whenever we write a program, we never allocate memory explicitly for simple variables. However, when we go to complex programming taking into account the basic data structures like trees, queues, and lists, etc. we need to allocate memory to these data structures explicitly. Because the size of these structures is very large compared to a simple integer type variable, so using the memory implicitly may end up in dumping the core of the code or it will result in segmentation faults if the size of allocated memory (initially to the code) is smaller than the size of the used memory (by the code during the execution of data structures).
Dynamic Memory Allocation in Heap
Hence to use the memory efficiently, wee explicitly allocate memory for these data structures, using the command given below,
void *malloc(size_t size)This type of allocated memory is stored in the memory segment heap. This allocated memory is not stored in an order, but it is stored randomly.
Comparsion between Stack vs Heap
The comparison between both the memory segments is shown in the figure below, pictorially.
Figure 3: Comparison between heap and stack
Problems:
The random allocation of memory in heap results in a lot of memory wastage (fragmentation) if heap memory is not managed efficiently as is obvious from the above figure.
Stack vs Heap Know the differences
| Stack | Heap | |
|---|---|---|
| Definition | The order of memory allocation is last in first out (LIFO). | Memory is allocated in random order while working with heap. |
| Growing direction | The direction of growth of stack is negative i.e. it grows in opposite direction as compared to memory growth. | The direction of growth of heap is positive, it grows in the same direction as that of the memory. |
| Flexibility | The size of the stack might be flexible or fixed e.g. it is fixed in Linux and variable in Windows operating system. | Heap is always variable. |
| Storage | It stores location counter, local variables and return address at the time of function calls. | It is used to store data that is dynamically allocated by the programmer in the program explicitly. |
| Problems | Shortage of memory, for instance, recursion without base case. | Memory wastage due to fragmentation because of random memory allocation. |
| Time to access | Access time is faster in stack. | Access time is slower in heap compared to stack. |
Conclusion
The purpose of both heap and stack is to save data, but they variate majorly in the type of data stored in them. For instance, stack stores data of functions to keep track of returning from function calls, however, heap is used to store data that is dynamically allocate by the user in the program i.e. using malloc or calloc.
- Different between Process and Program
- Different between Process and thread
- Difference between Memory and Registers
- Difference Between Microprocessor and Microcontroller
- Difference between RISC and CISC
- Difference between SRAM and DRAM
- Difference between external and internal fragmentation
- Difference Between Multiprogramming and Multitasking
- Difference between long-term and short-term scheduler in the operating system
- Difference between multiprocessor and multicomputer
- Difference between DDR2 and DDR3 Memory
- Difference between Windows and Linux