A voice recognition system involves biometric technology. This technology is getting very popular nowadays for security purposes and for electronics projects among engineering students. It can easily identify individuals on the basis of their voice, and the chances of theft and fraud are reduced. Other methods of biometric identification are iris/eye scans, fingerprints, face scans, hand prints, voice prints, handwriting, etc. Through the biometric voice recognition system, we can recognize an individual due to their unique voice characteristics. This security system has a wide range of applications and uses for ATM manufacturers, automobile manufacturers, and cell phone security access systems to eliminate any sort of theft or fraud. It also has many applications in embedded-based applications.

Voice Recognition System
The voice recognition system is the device’s capacity to understand speech instructions. It is essentially a type of embedded system. When we use it with a computer, it requires an ADC, which converts varying analog voice signals into digital pulses or digital signals, so the computer can easily understand. The hard drive already has the forms of speech stored in it. The voice signal is decoded and checked against the stored forms. Sometimes, due to the presence of other voices and noises, the output does not come out to be accurate.
Operation and Working – Voice Recognition Security System
In order to convert the speech or spoken words into a computer command, the computer performs several complex steps. The analog-to-digital converter converts the voice signal into a digital signal for the computer. The ADC digitizes the sound wave at frequent intervals by taking some precise measurements. This sampled or digitized sound is then filtered in order to remove noise. The purpose of this is to separate the sound into different bands of frequency. Sound also gets normalized by it. Different people have different speeds of speaking, so we need to adjust the sound so that it matches the speed of the sound template in the memory of the system.
The next step is to divide the signal into smaller segments of a few hundredths or thousandths of a second. Then match these signals with the collection of phonemes. The smallest element of any language is a phoneme. In the English language, there are approximately 40 phonemes. Different languages have different numbers of phonemes.

Next is the most difficult step in speech recognition. It includes the examination of phonemes in the context of other phonemes that are around them. A complex statistical model then examines the contextual phoneme plot, which it then compares with a large library of words, sentences, and phrases. Then the program finally determines the words of the user’s speech and displays the output as text or issues a command. The earlier speech recognition systems had a set of syntactical and grammatical rules; if the spoken words followed these rules, then the words could be determined. But human language cannot be modeled by just a set of rules.
Voice Recognition System Models
The speech recognition systems of modern times involve the use of more complex and powerful statistical modeling systems. Different mathematical functions and probability techniques determine the correct word or sentence. John Garofolo has proposed two models for it:
- Hidden Markov Model
- Neural Networks
The hidden Markov model is more important. According to this model, we consider a phoneme as a link in a chain, and the complete chain represents a word. To determine the next phoneme, the chain forms branches of different sounds that can come next; it gives a probability score to each branch off-phoneme on the basis of a built-in dictionary. Thus, determining the complete word.
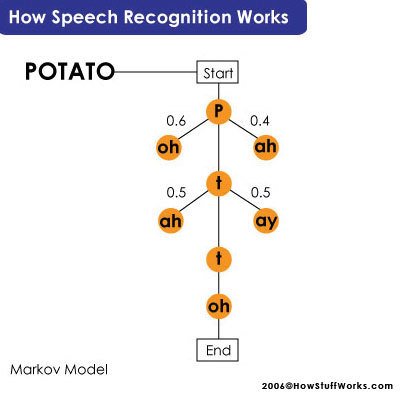
Hardware Design of Voice Recognition System
The hardware design of a very basic voice recognition security system involves three main elements:
- A microphone circuit.
- A microcontroller circuit.
- LCD Display.
The microphone circuit connects with the ADC of the controller. We store a set of words and phrases in the memory of the microcontroller. Once someone speaks a word in the mic, the ADC converts it into digital signals, which pass through digital filters and finally display on the LCD. Hence, the microcontroller decodes and displays the words spoken.

Speech Recognition Sensors
There are various sensors that can recognize speech; we will be mentioning the two main sensors below:
- Ultrasonic sensors
- Physiological sensors
1. ULTRASONIC SENSORS:
The ultrasonic processing is similar to radar. We throw an ultra-high-frequency acoustic tone at a moving object and record the reflections using a receiver. The Doppler effect governs the frequency of the tone reflected; the equation for it can be expressed as:
f = f0(1+ v c )
Here f0 is the emitted tone frequency, f is the reflected tone frequency, v is the velocity of reflecting surface towards the emitter and c is the speed of the sound
Thus, we can conclude that if the reflecting surface is moving far from the emitter, the frequency tone we record will be lower, and vice versa. The signal reflection will consist of a sum of sinusoids having different strengths and frequencies. In a case where a person is talking, the articulator motion during speech production will cause reflections. To differentiate between speech sounds, time frequency patterns can be of potential use.
2. PHYSIOLOGICAL SENSOR
It is a device developed at the Army Research Laboratory. This sensor physically attaches to a patient and records medical information such as the patient’s heartbeat and respiration. This sensor is worn around the throat.
It is useful in places where there is too much noise. The words that a person speaks in a microphone compare with the data from the physiological sensor present on the neck of the person, and then it determines the words or sentences easily.
Earlier, it was difficult to recognize speech using this sensor in IBM’s Via Voce because of the distortions in speech. But later on, Rockwell Science Center developed a hidden Markov model-based speech recognizer to be used with the physiological sensor.
These are the two common sensors that are currently available. Research and development on other types of voice recognition sensors is already in progress.
Classification of Voice Recognition System
There are four types of voice recognition systems.

- Isolated Voice Recognition System: This system requires a brief pause between the words spoken.
- Continuous Voice Recognition System: as the name suggests, this system does not require any pausing between the words.
- Speaker-dependent Voice Recognition System: This system identifies the speech from a single speaker only. That means only a certain speaker can get through this system.
- Speaker Independent Voice Recognition System: This system can identify the speech of any person.
Application of Voice Recognition System
In this section, we will discuss the application of voice recognition systems.
Voice Controlled Robotic Car
This car design requires operating through the interface of a human and a machine. The robotic vehicle performs its operations using voice commands from a human. It achieves this using an 89C51 controller with a voice recognition module such as HM2007, etc. Voice commands or push buttons control the direction of the robotic car. It uses RF to send voice signals or commands from the transmitter to the receiver end. The car can move left, right, forward, or backward, depending on the command that we give.
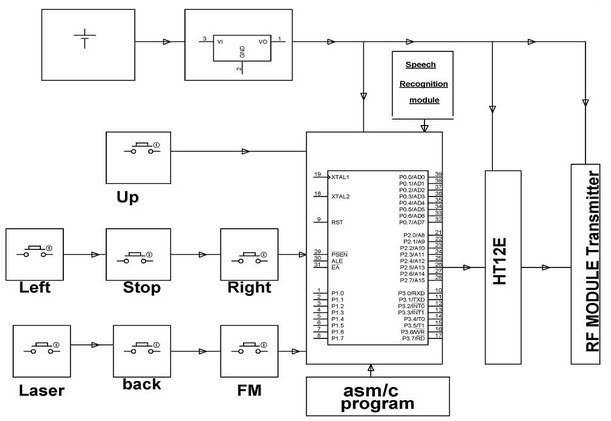
There are two motors that interface with the 89C51 microcontroller. These two motors control the movement of the robotic car. The RF transmitter converts and encodes the commands into digital data. The receiver circuit in the vehicle receives the data and decodes it to send it to another microcontroller, which can drive the DC motors. A motor driver IC helps to control the directions and movements of the car according to the decoded data of voice commands.
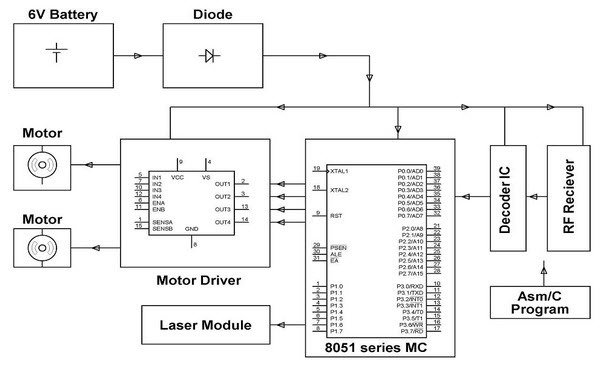
This voice-controlled vehicle can also operate with the help of DTMF technology for very long-range communication. Through DTMF, we can control the car from a mobile phone.
Conclusion
In conclusion, this tutorial provides an in-depth overview of voice recognition systems using microcontrollers. It covers a basic introduction along with models, designs, and types. At the end, we also discuss the applications to help us better understand the concept. You can utilize this to design and develop your own project on this topic. Hopefully, this was helpful in expanding your knowledge.
You may also like to read:
- ESP RainMaker with ESP32 using Google and Alexa Voice Assistant Integration
- Voice Controlled Robot using Arduino and Voice Recognition App
- Arduino L293D Motor Driver Shield Control DC, Servo, and Stepper Motors
- WiFi Controlled Robot using Arduino and Blynk App
- Difference Between C and Embedded C Language
- Difference Between Microprocessor and Microcontroller
Photo credits:
This concludes today’s article. If you face any issues or difficulties, let us know in the comment section below.
Hie can u provide guidance on Speaker Dependent sampling techniques if i want to carry out a project with Speaker dependency
I need my project done in 1 week is it possible? Voice recognition fan.
yes, it is possible. contact me at microcontrollerslabhub@gmail.com
hello mr bilal,
I want to purchase the full circuit with code
hello, thank you for your work, this was very enlightening.
I JUST WANT TO SAY THANK YOUUUUUU